Overview¶
Druid is an open source distributed data store. Druid’s core design combines ideas from OLAP/analytic databases, timeseries databases, and search systems to create a unified system for a broad range of use cases. Druid merges key characteristics of each of the 3 systems into its ingestion layer, storage format, querying layer, and core architecture.
Key Features¶
-
Column-oriented storage
Druid stores and compresses each column individually, and only needs to read the ones needed for a particular query, which supports fast scans, rankings, and groupBys.
-
Native search indexes
Druid creates inverted indexes for string values for fast search and filter.
-
Streaming and batch ingest
Out-of-the-box connectors for Apache Kafka, HDFS, AWS S3, stream processors, and more.
-
Flexible schemas
Druid gracefully handles evolving schemas and nested data.
-
Time-optimized partitioning
Druid intelligently partitions data based on time and time-based queries are significantly faster than traditional databases.
-
SQL support
In addition to its native JSON based language, Druid speaks SQL over either HTTP or JDBC.
-
Horizontal scalability
Druid has been used in production to ingest millions of events/sec, retain years of data, and provide sub-second queries.
-
Easy operation
Scale up or down by just adding or removing servers, and Druid automatically rebalances. Fault-tolerant architecture routes around server failures.
Architecture¶
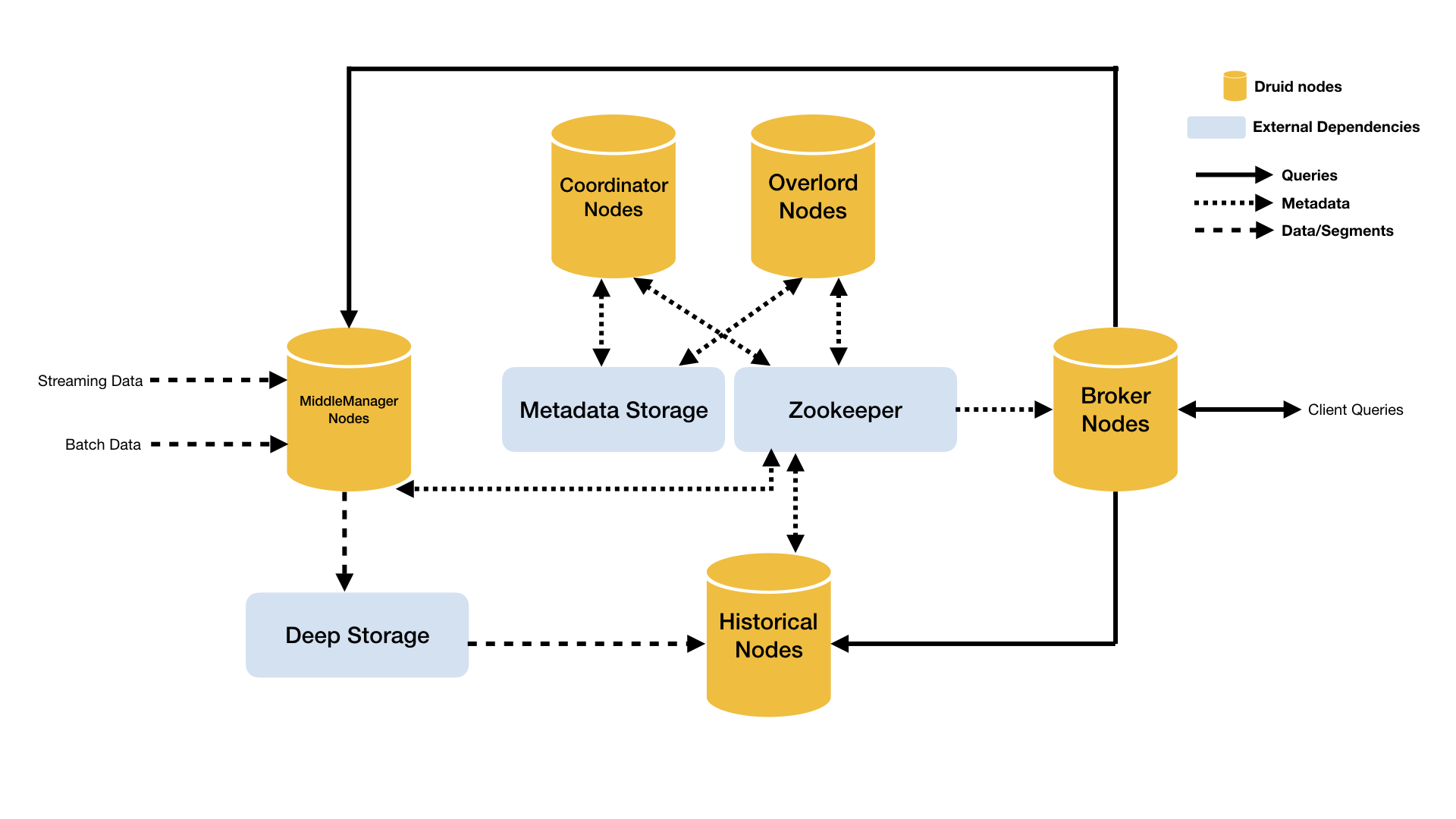
- 历史节点(Historical Node) :历史数据 Segment 的加载和查询
- 中间管理节点(MiddleManager Node):实时及离线数据摄入,生成 Segment
- 协调节点(Coordinator Node):对历史服务数据负载均衡
- 控制节点(Overlord Node):控制数据摄入分配,协调发布 Segment
- 查询节点(Broker Node):对外提供查询服务
- 路由节点(Router Node):统一API网关